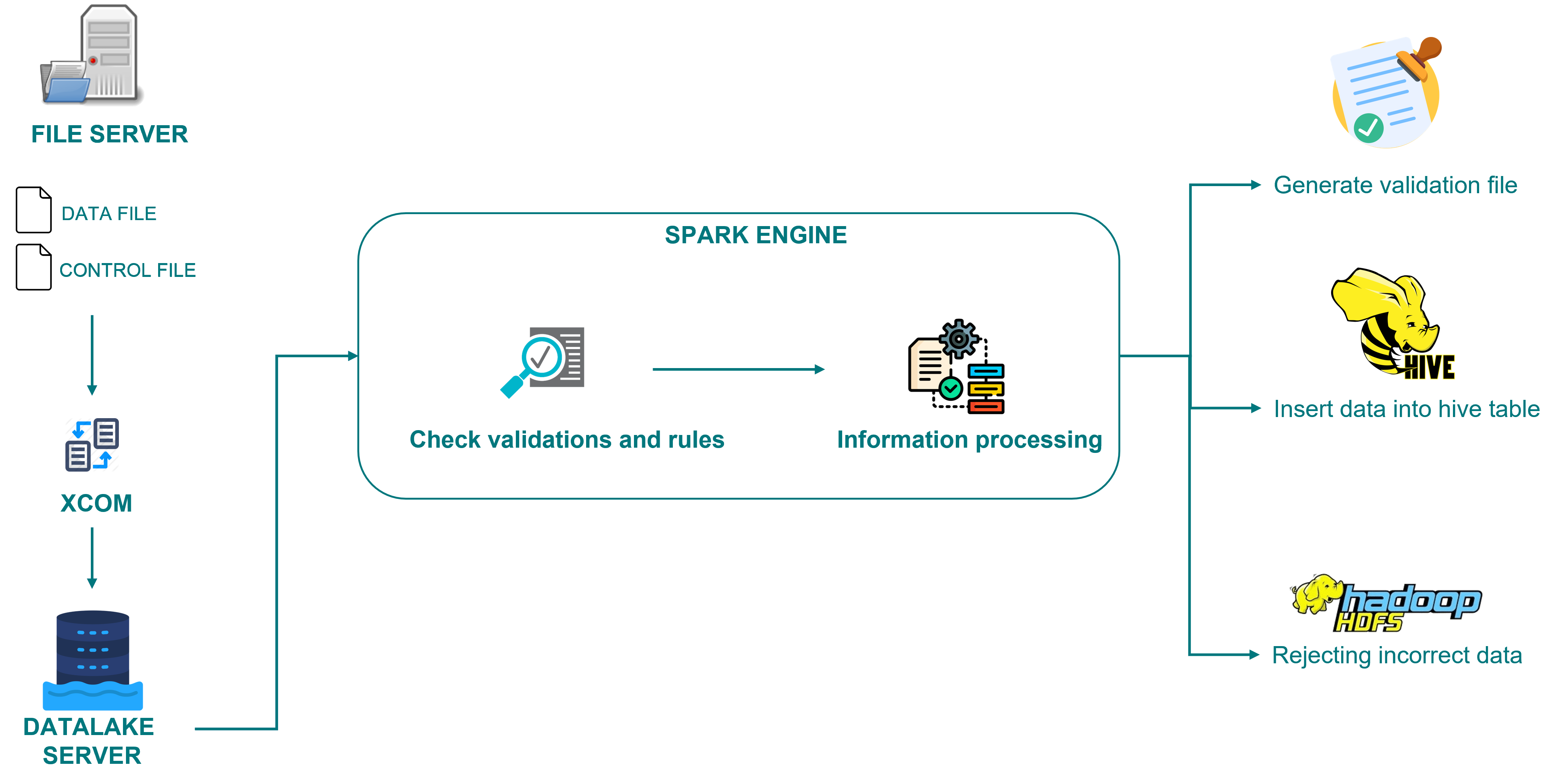
I worked on a project in which it was necessary to perform multiple ingests of information to the datalake (on-premise). Up to that moment, the client performed new ingests of information as 100% new developments, implementing validations and processing established by the users.
Performing ingests in this way mainly generated the following problems
- Repeated and not very scalable code. Repeated validations and processing, in case of a change it impacted on all the processes already developed.
- Very long development times.
To solve these problems, I proposed and implemented: “An ingest engine developed in pyspark”. The component was developed under the object-oriented programming paradigm, using the best development practices (clean code and SOLID).
This engine solved the 2 problems faced by the client in new developments:
Reusable and optimised code. The validations and processing that were performed in each new ingestion were encapsulated in the component so that they could be reused in new ingestions and in case of having to change/correct a validation, it was done in a single place.
Development times were reduced by 90%, since for new ingestions we limited ourselves to the use of the “engine”.
Languages/Technologies:
- python
- PySpark
- Hadoop
- Hive
- OOP
- SOLID, Clean Code
- Git (Bitbucket)
- Jenkins
- Bash